Using design patterns to build and maintain the Rule of Law
Abstract
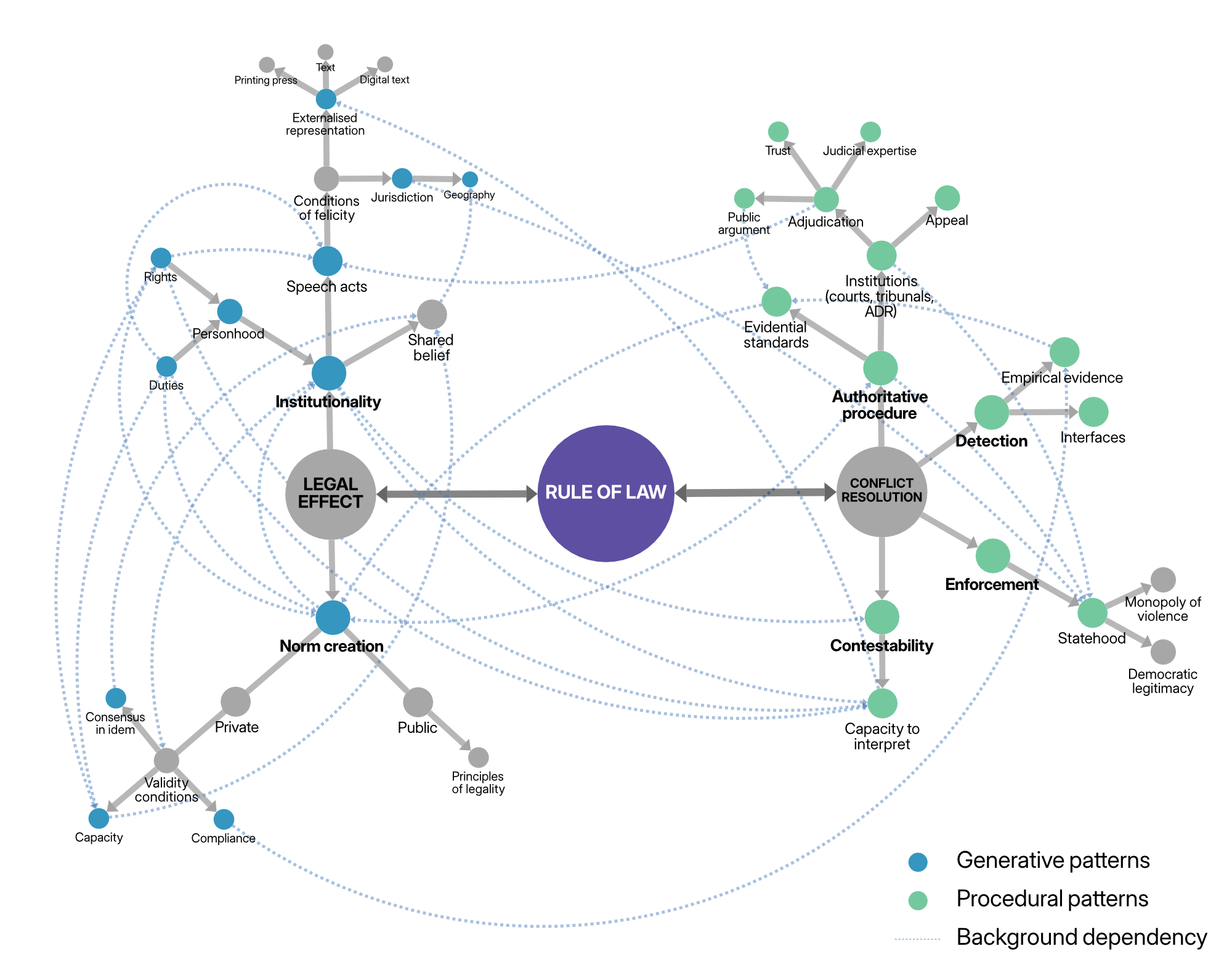
Law is, and has, an architecture. This article investigates that architecture by reference to the idea of ‘pattern languages’, as described in Alexander, Ishikawa, and Silverstein, A Pattern Language (OUP, 1977). Such ‘languages’ are combinations of design patterns, operating at multiple levels of abstraction and interlinking with one another to form a ‘fabric’ that constitutes the broader practice or enterprise. Applied to the legal domain, we can similarly identify patterns that operate at various levels, brought together into the idealised pattern language of legality and the Rule of Law. The article attempts to deconstruct the Rule of Law into its components. It presents two visual schemas showing those patterns and their dependencies, an initial narration of a selection of them, and example of how to ‘read’ the language. The goal is to provide a mechanism to assess which Rule of Law elements are present (or not) in a given instance, and also to identify what was absent in cases where we feel the ideal has failed to live up to its promise. It is also intended to contribute to the development of ‘legal tech’, by offering a mechanism of translation between Rule of Law values and software development practice. Ultimately, the goal is to foster legal and digital architectures that respect, sustain, and even strengthen legality and the Rule of Law.
(Open access pre-print here: https://osf.io/preprints/socarxiv/587zd. The publisher’s final version is available here)